
Blocking AI Bots From Scraping Websites Gets Boost From Cloudflare
6 months ago CryptoExpert
Cloudflare, a global internet security firm that claims to protect nearly 20% of the world’s web traffic, has launched what it calls an “easy button” for website owners who want to block AI services from accessing their content. The move comes as demand for content used to train AI models has skyrocketed.
Cloudflare’s core service, which serves as an internet proxy, scans and filters web traffic before it reaches websites. On average, the firm says its network sees over 57 million requests per second.
“To help preserve a safe internet for content creators, we’ve just launched a brand new ‘easy button’ to block all AI bots,” Cloudflare said in its announcement on Wednesday. “We hear clearly that customers don’t want AI bots visiting their websites, and especially those that do so dishonestly.”
While some AI companies properly identify their web scraping bots and respect website instructions to stay away, not all of them are transparent about their activities.

The new simple setting is being made available to all Cloudflare customers, including those on its free tier.
Dissecting AI bot activity
Along with its announcement, Cloudflare shared a plethora of information about the AI crawler activity it observes across its systems.
According to Cloudflare’s data, AI bots accessed around 39% of the top one million “internet properties” using Cloudflare in June. However, only 2.98% of these properties took measures to block or challenge those requests. Cloudflare also mentions that “the higher-ranked (more popular) an internet property is, the more likely it is to be targeted by AI bots.”
The firm said web crawlers operated by TikTok owner ByteDance, Amazon, Anthropic, and OpenAI were the most active. The top crawler was Bytedance’s Bytespider, which topped the charts in number of requests, the scope of its activity, and the frequency of being blocked. GPTBot, managed by OpenAI and used to collect training data for products like ChatGPT, ranked second in both crawling activity and blocks.
The web crawler for Perplexity, which has recently drawn controversy for its content crawling practices, was detected visiting a fraction of a percent of the sites Cloudflare protects.
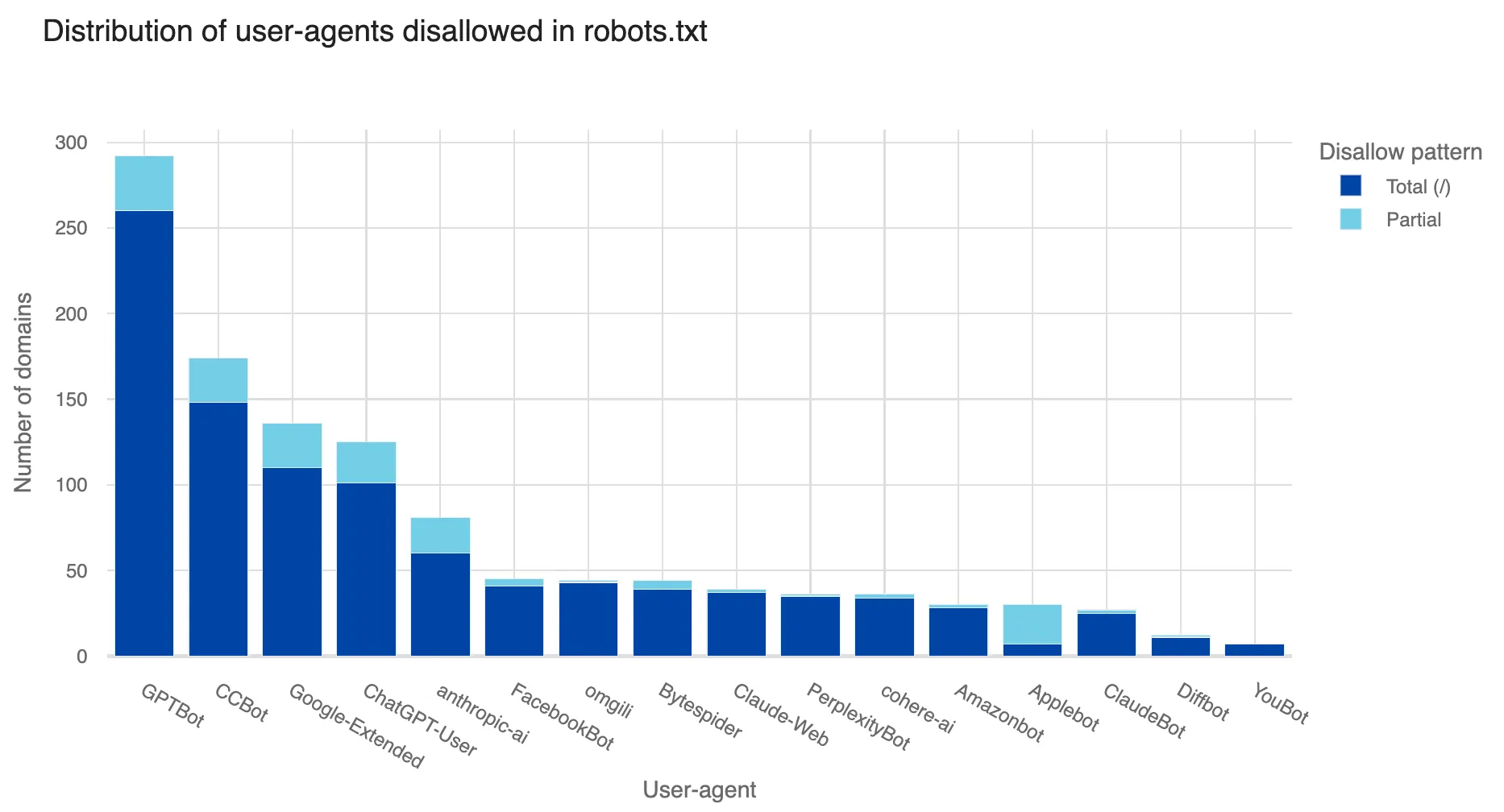
While website owners can implement their own rules to block known web crawlers, Cloudflare also said that most of its clients that do so are only blocking more mainstream AI developers like OpenAI, Google, or Meta, but not the top crawler from Bytedance or other companies.
AI versus AI
Cloudflare’s report highlighted how some AI bot operators are resorting to deceptive tactics to sidestep measures to block them, attempting to pass off their crawler activity as legitimate web traffic.
“Sadly, we’ve observed bot operators attempt to appear as though they are a real browser by using a spoofed user agent,” Cloudflare wrote.
As it turns out, AI is a key tool in the company’s arsenal to stop automated activity—whether from AI developers, search engines, or malicious attackers. Cloudflare said it uses a machine learning model to assign a “bot score” to each request made to a website protected by its services, with low scores indicating a low likelihood that the activity is legitimate.
With Cloudflare’s massive dataset on global internet traffic, the model takes into account a number of signals, including the request’s IP address, user agent, and behavior patterns, to determine the bot score.
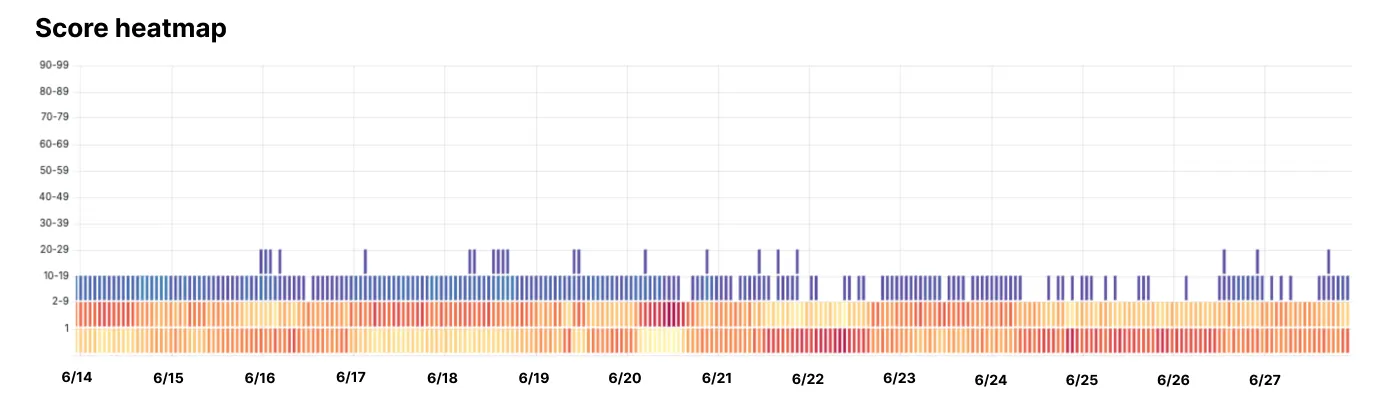
To illustrate this, Cloudflare said it looked at traffic from a specific bot known for its evasive behavior. The results were telling: all detections were scored below 30 out of 100, with the vast majority falling into the bottom two bands, indicating a score of 9 or less. In other words, even with attempts to obscure its source, the bot’s activity patterns gave it away—allowing Cloudflare to block it.
Protecting web content
Generative AI models rely on titanic volumes of existing content, much of it collected from across the web. In order for AI to continue to provide current information, its developers need to continue to collect information on a large scale.
Website owners and content creators are pushing back, with large publishers like news organizations taking legal action against AI companies. In the aforementioned case of Perplexity, publications like Forbes and Wired claim it is taking and republishing content without permission. Music publisher Sony preemptively warned over 700 tech firms to stay away in May, and this week, Warner Music Group has done the same.
The threat can be an existential one for publishers, should AI increasingly provide information to users without referring them to the source. A recent study published by SparkToro’s CEO Rand Fishkin suggested that 60% of people searching for information on Google stopped visiting the websites offering it because Google’s AI provided summarized answers immediately.
Edited by Ryan Ozawa.
Generally Intelligent Newsletter
A weekly AI journey narrated by Gen, a generative AI model.

























